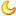Йигке§дђБэДяЪНЦЅХфЭјвГЭМЦЌЕижЗЕФЮЪЬт
ЮвЯыЛёШЁетИіЭјвГРяУцЕФЙЗЕФЫљгаЭМЦЌЃЌаДСЫвЛИіе§дђЯыЦЅХфЭМЦЌЕФЕижЗЃЌПЩЪЧВЛжЊЕРЮЊЪВУДЦЅХфВЛГіНсЙћЃЌЯТУцЪЧаЁДњТыЃЌЧѓжњИїЮЛДѓЩё ГЬађДњТыЃК
ГЬађДњТыЃК#!/usr/bin/python
# _*_ coding:utf-8 _*_
import re
import urllib
geturl = urllib.urlopen('http://tieba.baidu.com/p/4570256150')
urlcode = geturl.read()
imgre = r'src="(.*?fm=\d{3})"'
img = re.findall(imgre,urlcode)
print imgЯдЪОЕФНсЙћЪЧПеЕФСаБэЁЃЁЃЮвЪдЙ§АбЭМЦЌЕижЗжБНгИДжЦЯТРДЦЅХфЃЌЪЧПЩвдЦЅХфГЩЙІЕФЃЌЮЊЪВУДдкдДњТыжаОЭВЛааФиЃП